1. 기본 DML 튜닝
DML성능에 영향을 주는 요소와 튜닝 방법을 설명해보고, DML성능에 영향을 미치는 요소에 어떤 것들이 있는지 살펴보자.
🔎 DML성능에 영향을 미치는 요소
- 인덱스
- 무결성 제약
- 조건절
- 서브쿼리
- Redo 로깅
- Undo 로깅
- Lock
- 커밋
🔎 인덱스와 DML 성능
- 테이블에 레코드를 입력하면, 인덱스에도 입력해야 한다.(인덱스에 입력하는 과정이 더 복잡하므로, DML 성능에 미치는 영향도 더 크다.)
- 테이블은 Freelist를 통해 입력할 블록을 할당받지만, 인덱스는 정렬된 자료구조이므로 수직적 탐색을 통해 입력할 블록을 찾아야 한다.(*Freelist : 테이블마다 테이터 입력이 가능한 블록 목록)

- DELETE할때, 테이블에서 레코드 하나를 삭제하면, 인덱스 레코드를 모두 찾아서 삭제해줘야 한다.
- UPDATE할때, 변경된 컬럼을 참조하는 인덱스만 찾아서 변경해주면 된다.
- 단, 테이블에서 한 건 변경할 때마다 인덱스는 정렬된 자료구조이기때문에 두 개 오퍼레이션이 발생한다. 예) A가 K로 변경되면 저장위치도 달라져서 삭제 후 삽입하는 방식으로 처리함
- 인덱스 개수가 DML성능에 미치는 영향이 매우 크기때문에 인덱스 설계가 중요하다.
- 핵심 트랜잭션 테이블에서 인덱스 하나라도 줄이면 TPS(Transaction Per Second)는 그만큼 향상된다.
⚙️ 인덱스 개수가 DML 성능에 미치는 영향을 직접 테스트해보자!
create table source
as
select b.no, a.*
from (select * from emp where rownum <= 10) a
, (select rownum as no from dual connect by level <= 100000) b;
create table target
as
select * from source where 1 = 2;
alter table target add
constraint target_pk primary key(no, empno);▶ 방금 생성한 SOURCE 테이블에는 레코드 100만 개가 입력되어 있으며, TARGET 테이블은 현재 비어 있다.
TARGET 테이블에 PK 인덱스 하나만 생성한 상태에서 SOURCE 테이블을 읽어 레코드 100만 개를 입력해 보자.
set timing on;
insert into target
select * from source;
100000 개의 행이 만들어졌습니다.
경 과 : 00.00.04.95▶ 4.95초만에 수행을 마쳤다.
▶ 인덱스를 두 개 더 생성하고 다시 100만 건을 입력해보자!
truncate table target;
create index target_x1 on target(ename);
create index target_x2 on target(deptno, mgr);
insert into target
select * from source;
100000 개의 행이 만들어졌습니다.
경 과 : 00.00.38.98▶ 38.98초로 무려 여덟배나 느려질 정도로 인덱스 두 개의 영향력은 크다.
🔎 무결성 제약과 DML성능
데이터베이스에 논리적으로 의미있는 자료만 저장되게 하는 데이터 무결성 규칙으로는 아래 네가지가 있다.
- 개체 무결성(Entity Integrity)
- 참조 무결성(Referential Integrity)
- 도메인 무결성(Domain Integrity)
- 사용자 정의 무결성(또는 업무 제약 조건)
DBMS에서 PK,FK,Check,Not Null 같은 제약을 설정하면 데이터 무결성을 지킬 수 있다.
PK,FK 제약은 Check, Not Null 제약보다 성능에 더 큰 영향을 미친다.
> Check, Not Null은 정의한 제약 조건에 맞는지 확인하면 되지만, PK,FK 제약은 실제 데이터를 조회해봐야 하기 때문이다.
앞의 테스트를 이어 일반 인덱스, PK 제약을 모두 제거하고 100만건을 입력할때 걸리는 시간은?
drop index target_x1;
drop index target_x2;
alter table target drop primary key;
truncate table target;
insert into target
select * from source;
100000개의 행이 만들어졌습니다.
경 과 : 00:00:01.32- 테스트 결과를 요약하면 아래와 같다.
| PK 제약/인덱스 | 일반 인덱스(2개) | 소요시간(초) |
| O | O | 38.98 |
| O | X | 4.95 |
| X | X | 1.32 |
⚙️ 조건절과 DML성능
- 아래는 조건절만 포함하는 가장 기본적인 DML문과 실행계획이다.
set autotrace traceonly exp
update emp set sal = sal * 1.1 where deptno = 40;
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 7 | 2 (0)|
| 1 | UPDATE | EMP | | | |
| 2 | INDEX RANGE SACN | EMP_X01| 1 | 7 | 2 (0)|
---------------------------------------------------------------------------
delete from emp where deptno = 40;
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 13| 2 (0)|
| 1 | DELETE | EMP | | | |
| 2 | INDEX RANGE SACN | EMP_X01| 1 | 13| 2 (0)|
---------------------------------------------------------------------------- SELECT 문과 실행계획이 다르지 않기때문에 DML 문에는 인덱스 튜닝 원리를 그대로 적용가능하다.
⚙️ 서브쿼리와 DML성능
- 아래는 서브쿼리를 포함하는 DML문과 실행계획이다.
update emp e set sal = sal * 1.1
where exists
(select 'x' from dept where deptno = e.deptno and loc = 'CHICAGO');
delete from emp e
where exists
(select 'x' from dept where deptno = e.deptno and loc = 'CHICACO');
insert into emp
select e.*
from emp_t e
where exists
(select 'x' from dept where deptno = e.deptno and loc = 'CHICAGO')
- SELECT 문과 실행계획이 다르지 않으므로 DML문에는 조인 튜닝 원리를 그대로 적용할 수 있다.
⚙️ Redo로깅과 DML성능
- 오라클은 데이터파일과 컨트롤파일의 모든 변경사항을 Redo로그에 기록한다.
- Redo로그는 트랜잭션 데이터가 유실됐을때, 트랜잭션을 재현함으로써 유실 이전 상태로 복구하는데 사용된다.
- DML을 수행할 때마다 Redo로그를 생성해야 하므로 Redo로깅은 DML성능에 영향을 미친다.
✨Redo의 목적
1. Database Recovery
2. Cache Recovery (Instance Recovery 시 roll forward 단계)
3. Fast Commit
첫째, Redo 로그는 물리적으로 디스크가 깨지는 등의 Media Fail 발생 시 데이터베이스를 복구하기 위해 사용한다. 이때, 'Media recovery' 즉, 온라인 Redo 로그를 백업해 둔 Archived Redo 로그를 이용하게 된다.
둘째, Redo 로그는 'Cache Recovery'를 위해 사용하며, 다른 말로 'Instance Recovery'라고도 한다.
모든 DBMS가 버퍼캐시를 도입하는 이유가 I/O 성능을 높이기 위해서인데, 버퍼캐시는 휘발성이다.
캐시에 저장된 변경사항이 디스크 상의 데이터 블록에 아직 기록되지 않은 상태에서 정전 등이 발생해 인스턴스가 비정상적으로 종료되면, 그때까지의 작업내용을 모두 잃게 된다는 뜻이다. 이러한 트랜잭션 데이터 유실에 대비하기 위해 Redo 로그를 남긴다.
마지막으로, Redo 로그는 'Fast Commit'을 위해 사용한다.
변경된 메모리 버퍼블록을 디스크 상의 데이터 블록에 반영하는 작업은 랜덤 액세스 방식으로 이뤄지므로 매우 느리다. 반면 로그는 Append 방식으로 빠르게 로그 파일에 기록하고, 변경된 메모리 버퍼블록과 데이터파일 블록 간 동기화는 적절한 수단(DBWR, Checkpoint)을 이용해 나중에 배치(Batch) 방식으로 일괄 수행한다.
사용자의 갱신내용이 메모리상의 버퍼블록에만 기록된 채 아직 디스크에 기록되지 않았지만 Redo 로그를 믿고 빠르게 커밋을 완료한다는 의미에서 이를 'Fast Commit'이라고 부른다.
커밋 정보까지 Redo 로그 파일에 안전하게 기록했다면, 인스턴스 Crach가 발생해도 언제든 복구할 수 있으므로 오라클은 안심하고 커밋을 완료할 수 있다.
⚙️ Undo로깅과 DML성능
- 과거에는 롤백이라는 용어를 사용했지만, 현재는 Undo라는 용어로 사용된다.
- Redo는 트랜잭션을 재현함으로써 과거를 현재 상태로 되돌리는 데 사용한다.
- Undo는 트랜잭션을 롤백함으로써 현재를 과거 상태로 되돌리는 데 사용한다.

- 따라서 Redo에는 트랜잭션을 재현하는 데 필요한 정보를 로깅하고, Undo에는 변경된 블록을 이전 상태로 되돌리는 데 필요한 정보를 로깅한다.
- DML을 수행할 때마다 Undo를 생성해야 하므로 Undo 로깅은 DML 성능에 영향을 미친다. (그렇다고 Undo를 안 남길 순 없다. 오라클은 그런 방법을 아예 제공하지 않음
✨Undo의 용도와 MVCC 모델
오라클은 데이터를 입력, 수정, 삭제할 때마다 Undo 세그먼트에 기록을 남긴다. Undo 데이터를 기록한 공간은 해당 트랜잭션이 커밋하는 순간, 다른 트랜잭션이 재사용할 수 있는 상태로 바뀐다. 가장 오래 전에 커밋한 Undo 공간부터 재사용하므로 Undo 데이터가 곧바로 사라지진 않겠지만, 언젠가 다른 트랜잭션 데이터로 덮어쓰이면서(overwritten) 사라질 수 밖에 없다.
Undo에 기록한 데이터는 아래 세 가지 목적에 사용된다.
① Transaction Rollback
② Transaction Recovery (Instance Recovery 시 roll forward 단계)
③ Read Consistency
첫째, 트랜잭션에 의한 변경사항을 최종 커밋하지 않고 롤백하고자 할 때 Undo 데이터를 이용한다.
둘째, Instance Crach 발생 후 Redo를 이용해 roll forward 단계가 완료되면 최종 커밋되지 않은 변경사항까지 모두 복구된다. 따라서 시스템이 셧다운된 시점에 아직 커밋되지 않았던 트랜잭션들을 모두 롤백해야 하는데, 이때 Undo 데이터를 사용한다.
마지막으로, Undo 데이터는 '읽기 일관성(Read Consistency)'을 위해 사용한다. SQL 튜닝관점에서 주목할 내용은 읽기 일관성이다. 읽기 일관성을 위해 consistent 모드로 데이터를 읽는 오라클에선 동시 트랜잭션이 많을수록 블록 I/O가 증가하면서 성능 저하로 이어지기 때문이다.
🚩MVCC(Multi-Version Concurrency Control) 모델
MVCC 모델을 사용하는 오라클은 데이터를 두 가지 모드로 읽는다. 하나는 Currenct 모드, 다른 하나는 Consistent 모드다.
Currenct 모드 : 디스크에서 캐시로 적재된 원본(Current)블록을 현재 상태 그대로 읽는 방식
Consistent 모드 : 쿼리가 시작된 이후에 다른 트랜잭션에 의해 변경된 블록을 만나면 원본 블록으로부터 복사본(CR Copy)블록을 만들고, 거기에 Undo 데이터를 적용함으로써 쿼리가 '시작된 시점'으로 되돌려서 읽는 방식
🔎Lock과 DML성능
- Lock은 DML 성능에 크고 직접적인 영향을 미친다.
- Lock을 필요 이상으로 자주, 길게 사용하거나 레벨이 높일수록 DML 성능은 느려진다.
- 하지만, 반대로 Lock을 너무 적게, 짧게 사용하거나 필요한 레벨 이하로 낮추면 데이터 품질이 나빠진다.
- 성능과 데이터 품질 모두 중요하지만, 이 둘은 트레이드 오프(Trade-off)관계여서 어렵기에 세심한 동시성 제어가 필요하다.
- 동시성 제어(Concurrency Control) : 동시에 실행되는 트랜잭션 수를 최대화(고성능)하면서도 입력, 수정, 삭제, 검색 시 데이터 무결성을 유지(고품질)하기 위해 노력하는 것을 말한다.
🔎 커밋과 DML성능
- 커밋은 DML과 별개이지만, DML을 끝내려면 커밋까지 완료해야 하므로 서로 밀접한 관련이 있다.
- DML이 Lock에 의해 블로킹(Blocking)된 경우, DML을 완료할 수 있게 Lock을 푸는것이 커밋이다.
- 모든 DBMS가 Fast Commit을 구현하고 있다.
- 구현방식은 서로 다르지만, 갱신한 데이터가 아무리 많아도 커밋만큼은 빠르게 처리한다는 점은 같다.
(1) DB 버퍼캐시
▶ DB에 접속한 사용자를 대신해 모든 일을 처리하는 서버 프로세스는 버퍼캐시를 통해 데이터를 읽고 쓴다.
버퍼캐시에서 변경된 블록(Dirty 블록)을 모아 주기적으로 데이터파일에 일괄기록하는 작업은 DBWR(Database Writer)프로세스가 맡는다.
일을 건건이 처리하지 않고 모았다가 한 번에 일괄(Batch) 처리하는 방식이다.
(2) Redo 로그버퍼
▶ 버퍼캐시는 휘발성이므로 DBWR 프로세스가 Dirty 블록들을 데이터파일에 반영할 때까지 불안한 상태라고 생각할 수 있다.하지만, 버퍼캐시에 가한 변경사항을 Redo 로그에도 기록해 두었으므로 버퍼캐시 데이터가 유실되더라도 Redo 로그를 이용해 언제든 복귀가 가능하다.
Redo 로그는 파일이기때문에 Append 방식으로 기록하더라도 디스크 I/O는 느리다.
이러한 Redo 로깅 성능 문제를 해결하기 위해 오라클은 로그버퍼를 이용한다.
즉,Redo 로그 파일에 기록하기 전에 먼저 로그버퍼에 기록하는 방식이다. 로그버퍼에 기록한 내용은 나중에 LGWR(Log Writer) 프로세스가 Redo 로그 파일에 일괄(Batch) 기록한다.
(3) 트랜잭션 데이터 저장 과정
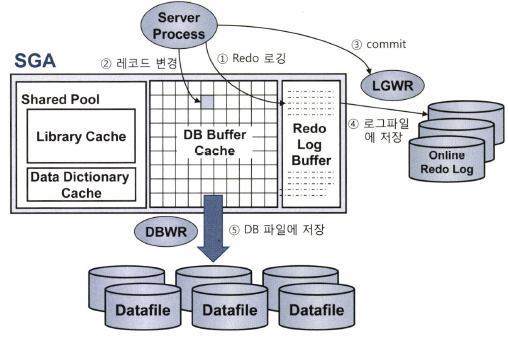
▶ 한 트랜잭션이 데이터를 변경하고 커밋하는 과정, 그리고 변경된 블록을 데이터파일에 기록하는 과정은 다음과 같다.
① DML 문을 실행하면 Redo 로그버퍼에 변경사항을 기록한다.
② 버퍼블록에서 데이터를 변경(레코드 추가/수정/삭제)한다. 물론 버퍼캐시에서 블록을 찾지 못하면 데이터파일에서 읽는 작업부터 한다.
③ 커밋한다.
④ LGWR 프로세스가 Redo 로그버퍼 내용을 로그파일에 일괄 저장한다.
⑤ DBWR 프로세스가 변경된 버퍼블록들은 데이터파일에 일괄 저장한다.
▶ 오라클은 데이터를 변경하기 전에 항상 로그부터 기록한다. 서버 프로세스가 버퍼블록에서 데이터를 변경(②)하기 전에 Redo 로그버퍼에 로그를 먼저 기록(①)하는 이유다.
DBWR 프로세스가 Dirty 블록을 디스크에 기록(⑤)하기 전에 LGWR 프로세스가 Redo 로그파일에 로그를 먼저 기록(④)하는 이유이기도 하다. (이를 'Write Ahead Logging'이라고 부른다.)
🚩 메모리 버퍼캐시가 휘발성이어서 Redo 로그를 남기는데, Redo 로그마저도 휘발성 로그버퍼에 기록한다면 트랜잭션 데이터를 안전하게 지킬 수 있는가? 커밋한 트랜잭션의 영속성을 어떻게 보장할 것인가? 오라클은 이 문제를 어떻게 해결할까?
잠자던 DBWR와 LGWR 프로세스는 '주기적으로'깨어나 각각 Dirty 블록과 Redo 로그버퍼를 파일에 기록한다. LGWR 프로세스는 서버 프로세스가 커밋을 발행했다가 '신호를 보낼때도' 깨어나서 활동을 시작한다.
'적어도 커밋시점에는' Redo 로그버퍼 내용을 로그파일에 기록한다는 뜻이다. (이를 'Log Force at Commit'이라고 부른다.)서버 프로세스가 변경한 버퍼블록들을 디스크에 기록하지 않았더라도 커밋 시점에 Redo 로그를 디스크에 안전하게 기록했다면, 그 순간부터 트랜잭션 영속성은 보장된다.
(4) '커밋 = 저장 버튼'
▶ 문서를 작성할 때 워드프로세서는 사용자가 입력한 내용을 메모리에 기록하며, 저장 버튼을 눌러야 비로소 디스크 파일에 저장한다. 워드프로세서가 저장을 완료할 때까지 사용자는 작업을 계속할 수 없다. (Sync 방식)
문서 저장과 관련해 안 좋은 습관 몇 가지를 나열하면 아래와 같다.
- 문서 작성을 모두 완료할 때까지 저장 버튼을 한 번도 누르지 않는다.
- 너무 자주, 수시로 저장 버튼을 누른다.
- 습관적으로 저장 버튼을 연속해서 두 번씩 누른다.
▶Redo 로그버퍼에 기록된 내용을 디스크에 기록하도록 LGWR 프로세스에 신호를 보낸 후 작업을 완료했다는 신호를 받아야 다음 작업을 진행할 수 있다. (Sync 방식)
LGWR 프로세스가 Redo 로그를 기록하는 작업은 디스크 I/O 작업이므로, 커밋은 느리다.
오랫동안 커밋하지 않은 채 데이터를 계속 갱신하면 Undo 공간이 부족해져 시스템 장애 상황을 유발할 수 있다.
루프를 돌면서 건건이 커밋한다면, 프로그램 자체 성능이 매우 느려진다.
🔎 데이터베이스 Call과 성능
- SQL 트레이스 리포트에서 Call 통계 부분만을 발췌한 것이다.

SQL 트레이스 Call통계가 보여주듯, SQL은 3단계로 나누어 실행된다.
- .Parse Call : SQL 파싱과 최적화를 수행하는 단계이다. SQL과 실행계획 라이브러리 캐시에서 찾으면 최적화 단계는 생략할 수 있다.
- Execute Call : 말그대로 SQL을 실행하는 단계이다. DML은 이 단계에서 모든 과정이 끝나지만 SELECT 문은 Fetch 단계이다.
- Fetch Call : 데이터를 읽어서 사용자에게 결과집합을 전송하는 과정으,로 SELECT문에서만 나타난다. 전송할 데이터가 많을 때는 Fetch Call이 여러번 발생한다.
Call이 어디서 발생하느냐에 따라 User Call과 Recursive Call로 나눌 수도 있다.

User Call은 네트워크를 경유해 DBMS 외부로부터 인입되는 Call이다.
최종 사용자(user)는 맨 왼쪽 클라이언트 단에 위치하지만, DBMS입장에서 사용자는 WAS다.
3-Tier 아키텍처에서 User Call은 WAS서버에서 발생하는 Call이다.
Recusive Call은 DBMS내부에서 발생하는 Call이다.
SQL파싱과 최적화 과정에서 발생하는 데이터 딕셔너리 조회, PL/SQL로 작성한 사용자 정의 함수/프로시저/트리거에 내장된 SQL을 실행할 때 발생하는 Call이 여기에 해당한다.
User Call이든 Recursive Call이든, SQL을 실행할 때마다 Parse, Execute, Fetch Call 단계를 거친다.
데이터베이스 Call이 많으면, 성능은 느릴수 밖에 없다. 특히, 네트워크를 경유하는 User Call이 성능에 미치는 영향은 매우 크다.
🔎 절차적 루프처리
- 데이터베이스 Call이 성능에 미치는 영향을 테스트를 통해 확인해보자!
create table source
as
select b.no, a.*
from (select * from emp where rownum <= 10) a,
(select rownum as no from dual connect by level <= 100000) b;
create table target
as
select * from source where 1 = 2;- 생성한 source 테이블에 레코드 100만개 입력되어 있다. source 테이블을 읽어 100만번 루프 돌면서 target 테이블에 입력해보자.
set timing on
begin
for s in (select * from source)
loop
insert into target values ( s.no, s.empno, s.ename, s.job, s.mgr
, s.hiredate, s.sal, s.comm, s.deptno );
end loop;
commit;
end;
경 과 : 00:00:29:31- 루프를 돌면서 건당 Call이 발생했지만, 네트워크 경유하지 않는 Recursive Call이므로 29초만에 수행을 마쳤다.
🔎 One SQL의 중요성
- Insert Into Select 구문으로 수행해보자!
insert into target
select * from source;
100000개의 행이 만들어졌습니다.
경 과 : 00:00:01.46▶ 한번의 Call로 처리하니 1.46초만에 수행을 마쳤다. 업무로직이 복잡해지면 절차적으로 처리할 수 밖에 없지만, 그렇지 않으면 One SQL로 구현하는게 좋다.
🚩절차적으로 구현된 프로그램을 One SQL로 구현 활용법
- Insert Into Select
- 수정가능 조인 뷰
- Merge 문
🔎 Array Processing 활용
- 실제 복잡한 업무 로직을 포함하는 경우가 많기 때문에 절차적 프로그램을 One SQL로 구현하기가 쉽지 않다
- 그럴때 Array Processing 기능을 활용하면 One SQL로 구현하지 않고도 Call 부하를 획기적으로 줄일 수 있다.
- Call을 단 하나로 줄이지 못하더라도, Array Processing을 활용하면 10-100번 수준으로 줄일 수 있다면, One SQL에 준하는 성능효과를 얻을 수 있다.
🔎 인덱스 및 제약 해제를 통한 대량 DML 튜닝
- 인덱스와 무결성 제약 조건은 DML 성능에 큰 영향을 끼친다.
- 동시 트랜잭션 없이 대량 데이터를 적재하는 배치 프로그램에서는 이들 기능을 해제함으로써 큰 성능개선 효과를 얻을 수 있다. (하지만 온라인 트랜잭션 처리 시스템에서 이들 기능을 해제할 순 없다. )
⚙️ 아래와 같이 테이블과 인덱스를 생성해보자! 테스트보다 데이터를 열배 더 늘려 SOURCE 테이블에 1,000만건을 입력했다.
create table source
as
select b.no, a.*
from (select * from emp where rownum <= 10) a
, (select rownum as no from dual connect by level <= 1000009) b:
create table target
as
select * from source where 1 = 2;
alter table target add constraint target_pk primary key(no, empno);
create index target_x1 on target (ename);PK제약을 생성하면 Unique인덱스가 자동으로 생성된다. 추가로 일반 인덱스를 하라 더 만들었으므로 인덱스는 총 두개다.
여기서! Target테이블에 1,000만건을 입력해보면 어떨까?
set timing on;
insert /*+ append */ into target
select * from source;
10000000 개의 행이 만들어졌습니다.
경과: 00:01:19.10
commit;- PK제약과 인덱스가 있는 상태에서 1분 19초가 걸렸다.
⚙️ PK제약과 인덱스 해제 1-PK제약에 Unique인덱스를 사용한 경우
- PK제약과 인덱스를 해체한 상태에서 데이터를 입력해보자!
trucate table target;
alter table target modify constraint target_pk disable drop index;- PK제약을 비활성화하면서 인덱스도 Drop했다.
alter index target_x1 unusable;- 일반 인덱스를 Unusable 상태로 변경했다.
- 인덱스가 Unusable인 상태에서 데이터를 입력하려면 skip_unusable_indexes 파라미터를 true로 설정해야한다. 기본 값이 true이므로 이전에 변경한 적 없다면, 굳이 설정을 변경하지 않아도 된다.
alter session set skip_unusable_index = true;무결성 제약과 인덱스를 해제함으로써 빠르게 INSERT할 준비가 됐다. 다시 1,000만 건을 입력해보자.
insert /*+ append */ into target
select * from source;
10000000 개의 행이 만들어졌습니다.
경과: 00:00:05.84
commit;이번에 5.84초만에 수행을 마쳤다. 이제 PK제약을 활성화하고 일반 인덱스를 재생성하면 모든 작업이 끝난다. PK제약을 활성화하면 PK인덱스는 자동으로 생성된다.
alter table target modify constraint target_pk enable NOVALIDATE;
경과: 00:00:06.77
alter index target_x1 rebuild;
경과: 00:00:08.26데이터 입력시간과 제약 활성화 및 인덱스 재생성 시간을 합쳐도 기존(1분 19초)보다 더 빨리 작업이 끝났다. 인덱스 및 무결성 제약이 DML성능에 미치는 영향을 볼 수 있다.
PK제약을 활성화하면서 NOVALIDATE옵션을 사용하면 시간을 단축시킬 수 있고, 이것은 기입력된 데이터에 대한 무결성 체크를 생략하도록 하는 옵션이다.
데이터 무결성에 확신이 없다면, 데이터를 입력하기 전에 아래 쿼리로 확인하면 된다.
select no, empno, count(*)
from source
group by no, empno
having count(*) > 1;⚙️ PK제약과 인덱스 해제2-PK제약에 Non-Unique인덱스를 사용한 경우
- PK인덱스를 Drop하지 않고 Unusable상태에서 데이터를 입려하고 싶다면 PK제약에 Non-Unique인덱스를 사용하면 된다.
set timing off;
truncate table target;
alter table target drop primary key drop index;
create index target_pk on target(no, empno); -- Non-Unique 인덱스 생성
alter table target add
constarint target_pk primary key (no, empno)
using index target_pk; -- pk 제약에 Non-unique 인덱스 사용하도록 지정- PK제약을 비활성화하고, 인덱스를 Unusable상태로 변경하자! PK제약을 비활성화했지만, 인덱스는 Drop하지 않고 남겨놨다. (대량 INSERT 작업을 진행하는데 문제가 없다)
alter table target modify constraint target_pk disable keep index;
alter index target_pk unsuable;
alter index target_x1 unusable;- 작업이 끝나면, 인덱스를 재생성하고, PK제약을 다시 활성화한다.
- 데이터 입력시간과 제약활성화 및 인덱스 재생성 시간을 합쳐도 기존(1분 19초)보다 훨씬더 빨리 끝난다.
alter index target_x1 rebuild;
경과: 00:00:97.24
alter index target_pk rebuild;
경과: 00:00:05.27
alter table target modify constraint target_pk enable novalidate;
경과: 00:00:00.06🔎 수정가능 조인 뷰
- 전통적인 방식의 UPDATE
update 고객 c
set 최종거래일시 = (select max(거래일시) from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)))
, 최근거래횟수 = (select count(*) from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)))
, 최근거래금액 = (select sum(거래금액) from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)))
where exists (select 'x' from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)));위의 쿼리를 아래쿼리로 변경했을때의 방식에서도 비효율이 없는 것은 아니다.
--위의 쿼리를 아래처럼 변경
update 고객 c
set (최종거래일시, 최근거래횟수, 최근거래금액) =
(select max(거래일시), count(*), sum(거래금액)
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)))
where exists (select 'x' from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)));총 고객 수가 아주 많다면 Exists서브쿼리를 아래와 같이 해시세미 조인으로 유도하는 것을 고려할 수 있다.
update 고객 c
set (최종거래일시, 최근거래횟수, 최근거래금액) =
(select max(거래일시), count(*), sum(거래금액)
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)))
where exists (select **/*+ unnest hash_sj */** 'x' from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)));만약 한달 이내 거래를 발생시킨 고객이 많아 UPDATE 발생량이 많다면, 아래와 같이 변경하는 것을 고려할 수도 있다.
허나 모든 고객 레코드에 LOCK이 걸리고, 이전과 같은 값으로 갱신되는 비중이 높을 수록 Redo로그 발생량이 증가하며 오히려 비효율적일 수 있다.
update 고객 c
set (최종거래일시, 최근거래횟수, 최근거래금액 ) =
(select nvl(max(거래일시), c.최종거래일시)
,decode(count(*), 0, c.최근거래횟수, count(*))
,nvl(sum(거래금액), c.최근거래금액)
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(add_months(sysdate, -1)));이처럼 다른 테이블과 조인이 필요할 때 전통적인 UPDATE문을 사용하면 비효율을 완전히 해소할 수 없다
🔎 수정가능 조인 뷰
- 수정가능 조인뷰를 활용하면 참조테이블과 두 번 조인하는 비효율을 없앨수 있다.
update
(select /*+ ordered use_hash(c) no_merge(t) */
c.최종거래일시, c.최근거래횟수, c.최근거래금액
, t.거래일시, t.거래횟수, t.거래금액
from (select 고객번호, max(거래일시) 거래일시, count(*) 거래횟수, sum(거래금액) 거래금액
from 거래
where 거래일시 >= trunc(add_months(sysdate, -1))
group by 고객번호) t, 고객 c
where c.고객번호 = t.고객번호
)
set 최종거래일시 = 거래일시
, 최근거래횟수 = 거래횟수
, 최근거래금액 = 거래금액▶ '조인 뷰'는 From절에 두개 이상 테이블을 가진 뷰를 말하며, 수정가능 조인 뷰는 입력, 수정, 삭제가 허용되는 조인뷰이다.단, 1쪽 집합과 조인하는 M쪽 집합에만 입력, 수정, 삭제가 허용된다.
- 아래와 같이 조인뷰를 통해 job = ‘CLERK’ 인 레코드 loc을 모두 ‘SEOUL’로 변경을 허용하면?
create table emp as select * from scott.emp;
create table dept as select * from scott.dept;
select e.rowid emp_rid, e.*, d.rowid dept_rid, d.dname, d.loc
from emp e, dept d
where e.deptno = d.deptno;
update emp_dept_view set loc = 'SEOUL' where job = 'CLERK'- job = ‘CLERK’인 사원이 10,20,30 부서에 모두 속해있는데 UPDATE를 수행하고 나면 세 부서의 소재지가 모두 사원 뿐만 아니라 다른 job을 가진 사원의 부서 소재지까지 바뀐다.
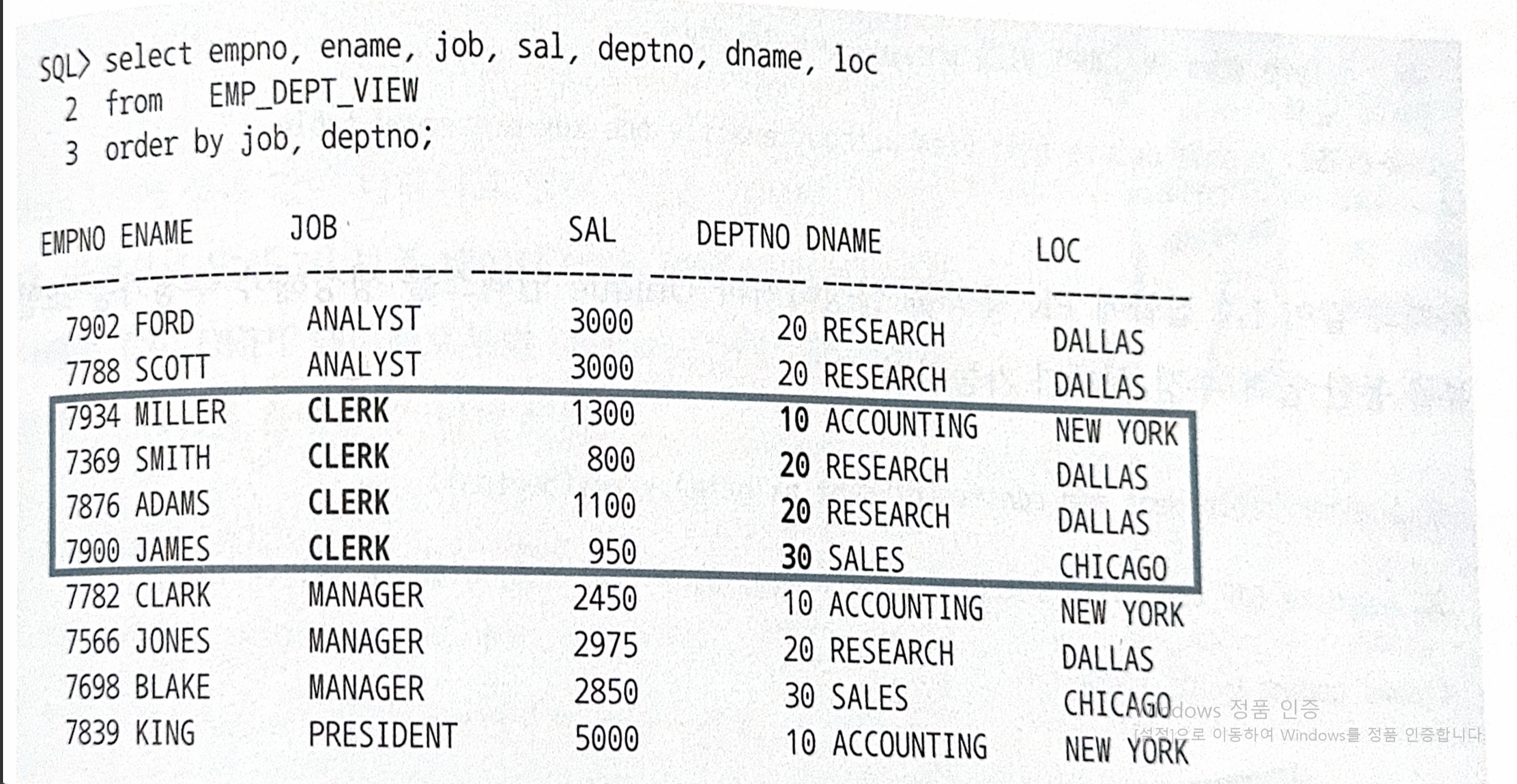
PK 제약을 설정하면, EMP 테이블은 '키-보존 테이블'이 되고 DEPT 테이블은 '비 키-보존 테이블'로 남는다.
🔎 키 보존 테이블이란?
- 키보존 테이블 : 조인된 결과집합을 통해서도 중복 값 없이 Unique하게 식별이 가능한 테이블을 말한다. Unique한 1쪽 집합과 조인되는 테이블이어야 조인된 결과집합을 통한 식별이 가능하다.
- 뷰에 rowid를 제공하는 테이블
⚙️ ORA-01779 오류 회피
- 아래와 같이 DEPT 테이블에 AVG_SAL컬럼을 추가하자!
alter table dept add avg_sal number(7,2);- EMP로부터 부서별 평균 급여를 계산해서 방금 추가한 컬럼에 반영하는 UPDATE문이다.
update
(select d.deptno, d.avg_sal as d_avg_sal, e.avg_sal as e_avg_sal
from (select deptno, round(avg(sal), 2) avg_sal from emp group by deptno) e
, dept d
where d.deptno = e.deptno)
set d_avg_sal = e_avg_sal;- 11g 이하 버전에 위 UPDATE문을 실행하면 ORA-01779 에러가 발생한다.
ORA-01779: cannot modify a column which maps to a non key-preserved table- EMP 테이블을 deptno로 Group by 했으므로 DEPTNO컬럼을 조인한 DEPT 테이블은 키가 보존되는데도 옵티마이저가 불필요한 제약을 가한 것이다.
- bypass_ujvc : 해당 힌트를 이용해 제약을 회피할수 있으며, Updatetable Join View Check를 생략하라고 옵티마이저에 지시하는 힌트이다
update /*+ bypass_ujvc */
(select d.deptno, d.avg_sal as d_avg_sal, e.avg_sal as e_avg_sal
from (select deptno, round(avg(sal), 2) avg_sal from emp group by deptno) e
, dept d
where d.deptno = e.deptno)
set d_avg_sal = e_avg_sal;11g부터 해당 힌트를 사용할 수 없게 되었고, UPDATE문을 실행할 방법이 없으므로 MERGE문으로 변경해줘야 한다.
하지만, bypass_ujvc힌트사용이 중단되었을 뿐 수정가능 조인 뷰 사용은 중단되지 않았다!
11g에서도 1쪽집합에 Unique인덱스가 있으면 수정가능 조인 뷰를 이용한 UPDATE가 가능하다.
🔎 Merge문 활용
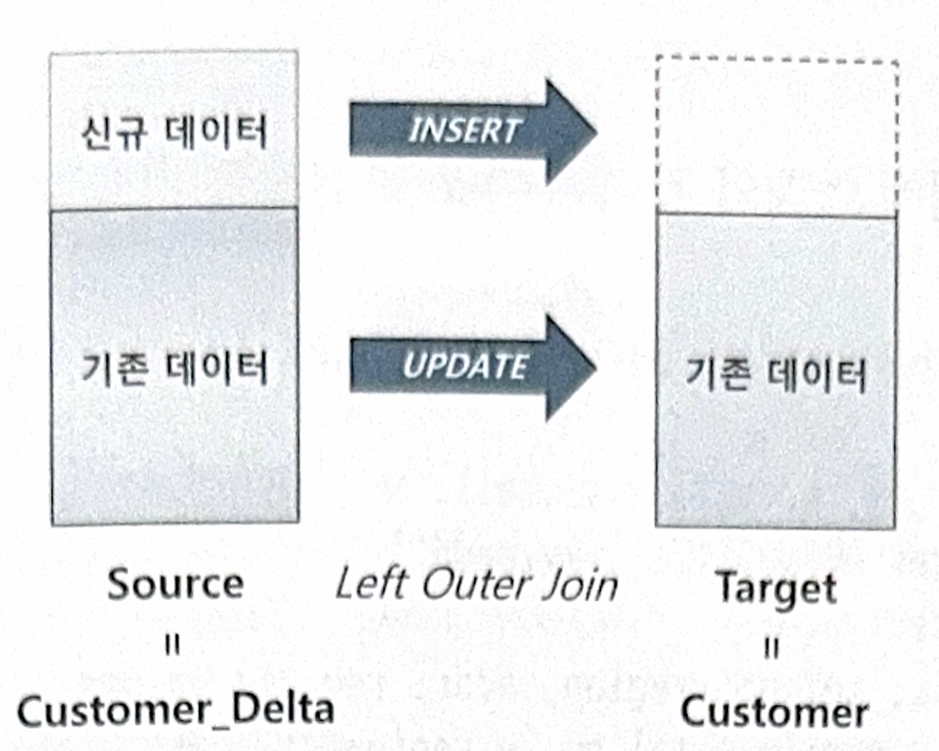
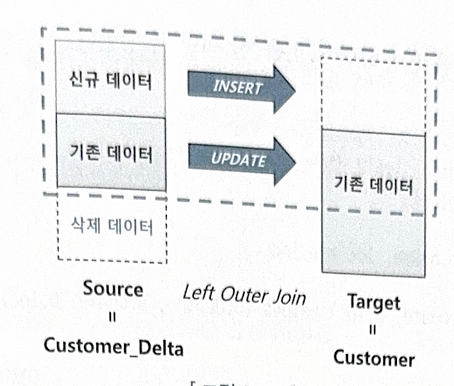
- DW에서 가장 흔히 발생하는 오퍼레이션은 기간계 시스템에서 가져온 신규 트랜잭션 데이터를 반영함으로써 두 시스템 간 데이터를 동기화하는 작업이다.
▶ 고객테이블에 발생한 변경분 데이터를 DW에 반영하는 프로세스는 다음과 같다.
이중에서 3번 데이터 적재 작업을 효과적으로 지원하기 위해 오라클 9i에서 MERGE문이 도입됐다.
1. 전일 발생한 변경 데이터를 기간계 시스템으로 추출(Extraction)
create table customer_delta
as
select * from customer
where mod_dt >= trunc(sysdate)-1
and mod_dt < trunc(sysdate);2. CUSTOMER_DELTA 테이블을 DW시스템으로 전송(Transportation)
3. DW시스템으로 적재(Loading)
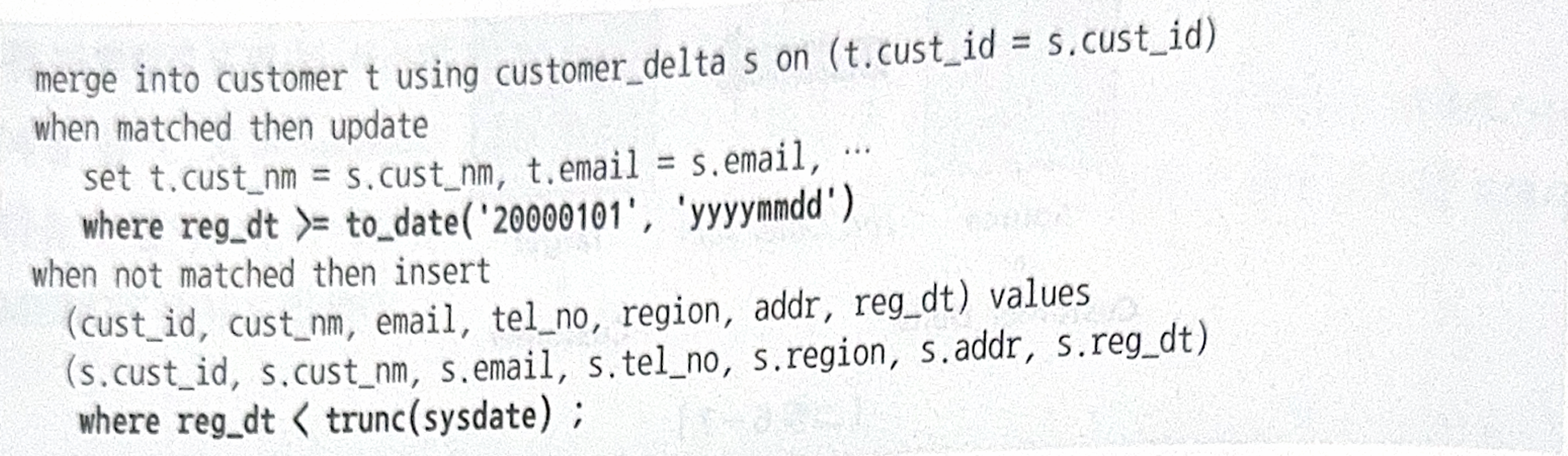
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update
set t.cust_nm = s.cust_nm, t.email = s.email ....
when not matched then insert
(cust_id, cust_nm, email, tel_no, region, addr, reg_dt) values
(s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt);- MERGE문은 Source 테이블 기준으로 Targer테이블과 Left Outer 방식으로 조인해서 조인에 성공하면 UPDATE, 실패하면 INSERT한다.
- MERGE문을 UPSERT(=UPDATE+INSERT)라고도 부른다.
- MERGER문에서 Source는 Customer_Delta테이블이고, Targer은 Customer테이블이다.
⚙️ Optional Clauses
- UPDATE와 INSERT를 선택적으로 처리할 수도 있다.

- 이 확장 기능을 통해 아래와 같이 수정가능 조인 뷰 기능을 대체할 수 있게 되었다.

⚙️ Conditional Operations
- ON절에 기술한 조인문 외에 아래와 같이 추가로 조건절을 기술할 수도 있다.
⚙️ DELETE Clause
- 이미 저장된 데이터를 조건에 따라 지우는 기능도 제공한다.
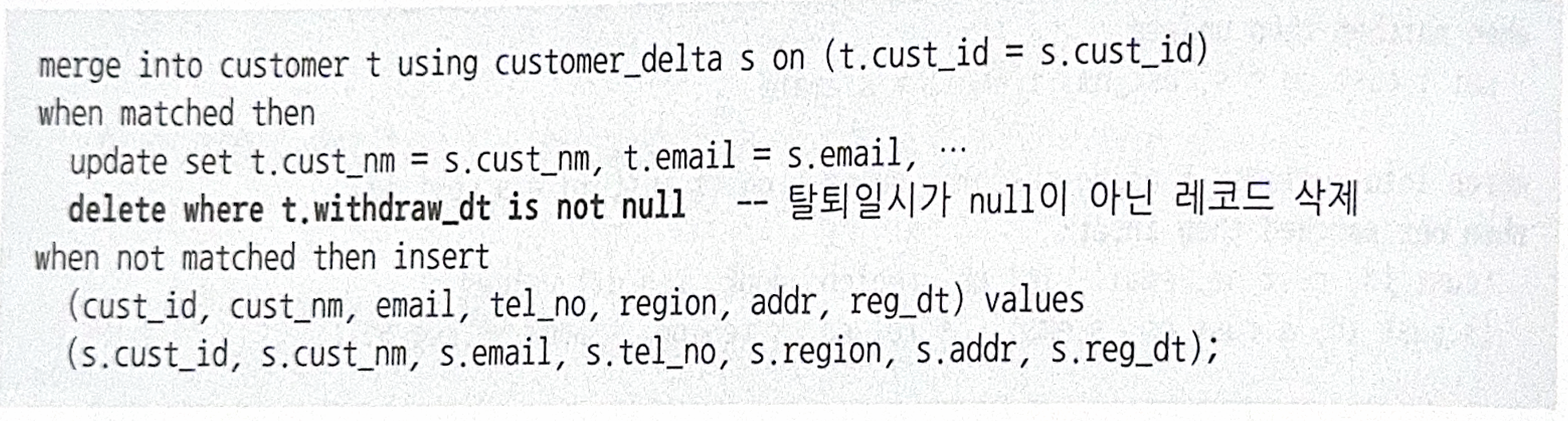
- MERGE문에서 UPDATE가 이루어진 결과로서 탈퇴일시가 Null이 아닌 레코드만 삭제한다. 즉, 탈퇴일시가 Null이 아니었어도 MERGE문을 수행한 결과 Null이면 삭제하지 않는다.
- MERGE문 DELETE절은 조인에 성공한 데이터만 삭제할 수 있다.
- Source(=Customer_Delta)테이블에서 삭제된 테이터는 Targer(=Customer)테이블에서도 지우고 싶을텐데, MERGE문 DELETE절은 Source에서 삭제된 데이터는 조인에 실패하기 때문에 해당 역할까지는 못한다.
- 조인에 실패한 데이터는 UPDATE할 수도 없고, DELETE할 수도 없다.
- DELETE절은 조인에 성공한 테이더를 모두 UPDATE하고서 그 결과 값이 DELETE WHERE조건절을 만족하면 삭제하는 기능이다.
⚙️ Merge Into 활용 예
저장하려는 레코드가 기존에 있던 것이면 UPDATE를 수행하고, 그렇지 않으면 INSERT하려고 한다.
그럴때 아래와 같이 처리하면 SQL을 항상 두번씩(SELECT 한번, INSERT 또는 UPDATE 한번)수행한다.

아래와 같이 SQL을 최대 두번 수행한다.

아래와 같이 MERGE문을 활용하면 SQL 한번만 수행한다.

2. Direct Path I/O 활용
온라인 트랜잭션은 기준성 데이터, 특정 고객, 특정 상품, 최근 거래등을 반복적으로 읽기 때문에 버퍼캐시가 성능 향상에 도움을 준다. 반면, 정보계 시스템이나 배치 프로그램에서 사용하는 SQL은 주로 대량 데이터를 처리하기 때문에 버퍼캐시를 경유하는 I/O메커니즘이 오히려 성능을 떨어뜨릴 수 있다.
🔎 Direct Path I/O
- 블록I/O는 DB버퍼캐시를 경유한다. 즉, 읽고자 하는 블록을 먼저 버퍼캐시에서 찾아보고, 찾지 못할 때만 디스크에서 읽는다.
- 데이터를 변경할 때도 먼저 블록을 버퍼캐시에서 찾는다. (찾은 버퍼블록에 변경을 가하고 나면, DBWR프로세스가 변경된 블록들을 주기적으로 찾아 데이터파일에 반영해준다.)
- 자주 읽는 블록에 대한 반복적인 I/O Call을 줄임으로써 시스템 전반적인 성능을 높이려고 버퍼캐시를 이용하지만, 대량 데이터를 읽고 쓸 때 건건이 버퍼캐시를 탐색한다면 개별프로그램성능에는 오히려 안 좋다. > 버퍼캐시에서 블록을 찾을 가능성이 거의 없기 때문이다.
- 대량 블록을 건건이 디스크로부터 버퍼캐시에 적재하고서 읽어야 하는 부담도 크고, 적재한 블록을 재사용할 가능성이 있느냐도 중요하다. (Full Scan위주로 가끔 수행되는 대용량 처리 프로그램이 읽어 들인 데이터는 대게 재사용성이 낮다.) > 데이터 블록들이 버퍼캐시를 점유한다면 다른 프로그램 성능에도 나쁜 영향을 미친다.
오라클은 버퍼캐시를 경유하지 않고 곧바로 데이터 블록을 읽고 쓸 수 있는 Direct Path I/O기능을 제공하는데, 아래는 그 기능을 작동하는 경우이다.
- 병렬 쿼리로 Full Scan을 수행할 때
- 병렬 DML을 수행할 때
- Direct Path Insert를 수행할 때
- Temp 세그먼트 블록들을 읽고 쓸 때
- direct 옵션을 지정하고 export를 수행할 때
- nocache 옵션을 지정한 LOB 컬럼을 읽을 때
🔎 Direct Path Insert
INSERT가 느린 이유는 아래와 같다.
- 데이터를 입력할 수 있는 블록을 Freelist에서 찾는다. 테이블 HWM(High-Water-Mark) 아래쪽에 있는 블록 중 데이터 입력이 가능한 블록을 목록으로 관리하는데, 이를 Freelist라고 한다.
- Freelist에서 할당받은 블록을 버퍼캐시에서 찾는다.
- 버퍼캐시에 없으면, 데이터파일에서 읽어 버퍼캐시에 적재한다.
- INSERT 내용을 Undo 세그먼트에 기록한다.
- INSERT 내용을 Redo 로그에 기록한다.
Direct Path Insert 방식을 사용하면, 대량 데이터를 일반적인 INSERT 보다 훨씬 더 빠르게 입력할 수 있다.
데이터 Direct Path Insert 방식으로 입력하는 방법은 아래와 같다.
- INSERT... SELECT 문에 append 힌트 사용
- parallel 힌트를 이용해 병렬 모드로 INSERT
- direct 옵션을 지정하고 SQL Loader로 데이터 적재
- CTAS(create table... as select) 문 수행
Direct Path Insert 방식이 빠른 이유는 아래와 같다.
- Freelist를 참조하지 않고 HWM 바깥 영역에 데이터를 순차적으로 입력한다.
- 블록을 버퍼캐시에서 탐색하지 않는다
- 버퍼캐시에 적재하지 않고, 데이터파일에 직접 기록한다.
- Undo 로깅을 안 한다.
- Redo 로깅을 안 하게 할 수 있다. 테이블을 nologging 모드로 전환한 상태에서 Direct Path Insert 하면 된다.
- alter table t NOLOGGING;
- 참고) Direct Path Insert가 아닌 일반 INSERT문을 로깅하지 않게 하는 방법은 없다.
- Array Processiong도 Direct Path Insert 방식으로 처리할 수 있다. (append_values 힌트를 사용)
⚙️ Direct Path Insert를 사용할때의 주의점
첫째, 이 방식을 사용하면 성능은 비교할 수 없이 빨라지지만 Exclusive 모드 TM Lock이 걸린다는 사실이다.
따라서, 커밋하기 전까지 다른 트랜잭션은 해당 테이블에 DML을 수행하지 못한다.
둘째, Freelist를 조회하지 않고 HWM 바깥영역에 입력하므로 테이블에 여유 공간이 있어도 재활용하지 않는다는 사실이다.
과거 데이터를 기준으로 DELETE해서 여유공간이 생겨도 이 방식으로만 계속 INSERT하는 테이블은 사이즈가 줄지 않고 계속 늘어만 간다.
Range 파티션 테이블이면 과거테이블 데이터를 DELETE가 아닌 파티션 DROP방식으로 지워야 공간 반환이 제대로 이루어진다.비파티션 테이블이면 주기적으로 Reorg 작업을 수행해줘야 한다.
🔎 병렬 DML
- INSERT는 append 힌트를 이용해 Direct Path Write방식으로 유도할 수 있지만 UPDATE, DELETE는 Direct Path Write가 불가능하다. > 유일한 방법은 병렬 DML로 처리하는 것
- 병렬처리는 대용량 데이터가 전제이므로 오라클은 병렬 DML에 항상 Direct Path Wirte방식을 사용한다.
alter session enable parallel dml;- 각 DML문에 아래와 같이 힌트를 사용하면, 대상 레코드를 찾는 작업(INSERT는 SELECT쿼리, UPDATR/DELETE는 조건절 검색)은 데이터 추가/변경/삭제도 병렬로 진행한다.
insert /*+ parallel(c 4) */ into 고객 c
select /*+ full(o) parallel(o 4) */ * from 외부가입고객 o;
update /*+ full(c) parallel(c 4) */ 고객 c set 고객상태코드 = 'WD'
where 최종거래일시 < '20100101';
delete /*+ full(c) parallel(c 4) */ from 고객 c
where 탈퇴일시 < '20100101';🚩힌트를 기술했지만, 실수로 병렬 DML을 활성화하지 않으면 어떻게 될까?
> 대상 레코드를 찾는 작업은 병렬로 진행하지만, 추가/변경/삭제는 Query Coordinatior가 혼자 담당하므로 병목이 생긴다.
병렬 INSERT는 append 힌트를 지정하지 않아도 Direct Path Insert 방식을 사용한다.
- 병렬 DML이 작동하지 않을 경우, append 힌트를 같이 사용하는 게 좋다. 혹시라도 병렬 DML이 작동하지 않더라도 QC가 Direct Path Insert를 사용하면 어느 정도 만족할 만한 성능을 낼 수 있기 때문이다.
insert /*+ append parallel(c 4) */ into 고객 c
select /*+ full(o) parallel(o 4) */ * from 외부가입고객 o;- 12c부터는 enable_parallel_dml 힌트도 지원된다.
insert /*+ append parallel(c 4) */ into 고객 c
select /*+ full(o) parallel(o 4) */ * from 외부가입고객 o;
update /*+ enable_paralLel_dml full(c) parallel(c 4) */ с
set 고객상태코드 = 'WD'
where 최종거래일시 20100101';
delete /*+ enable_parallel_dml fulL(c) parallel(c 4) */ from c
where 탈퇴일시 < 20100101;- 병렬 DML도 Direct Path Write 방식 사용하므로, 테이블에 입력/수정/삭제할때 Exclusive 모드 TM Lock이 걸린다.
- 트랜잭션이 빈번한 주건에 이 옵션을 사용하는 것은 금물이다.
⚙️ 병렬 DML이 잘 작동되는지 확인하는 방법
- DML작업을 각 병렬 프로세스가 처리하는지, QC가 처리하는지를 실행계획에서 확인할 수 있다.
- 아래와 같이 UPDATE가 PX COORDINATOR 아래쪽에 나타나면 UPDATE를 각 병렬 프로세스가 처리한다.


'Study > 친절한 SQL 튜닝' 카테고리의 다른 글
| [DB] 7장. SQL 옵티마이저 (0) | 2025.04.27 |
|---|---|
| [DB] 6장. DML 튜닝(2) (0) | 2025.04.20 |
| [DB] 5장. 소트 튜닝 (0) | 2025.03.17 |
| [DB] 4장. NL조인 (0) | 2025.02.25 |
| [DB] 3장. 인덱스 튜닝(2) (0) | 2025.01.31 |